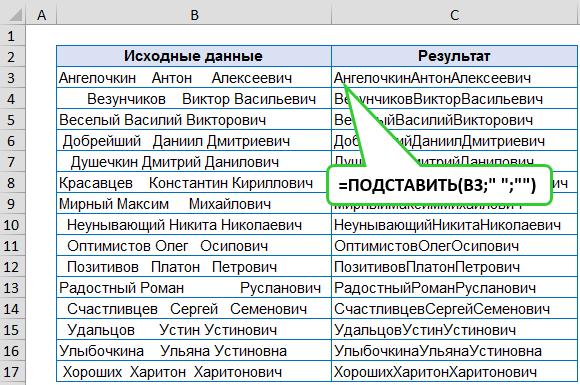
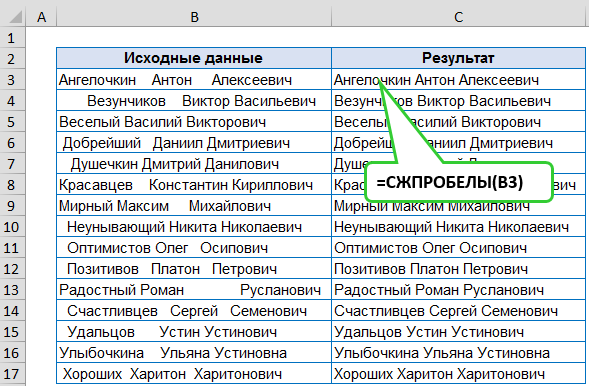
Создание зависимых списков с изменяемым источником
| Категория: Приемы и советы, Работа с данными ячеек, Формулы и функции | Опубликовано 13-11-2015
15
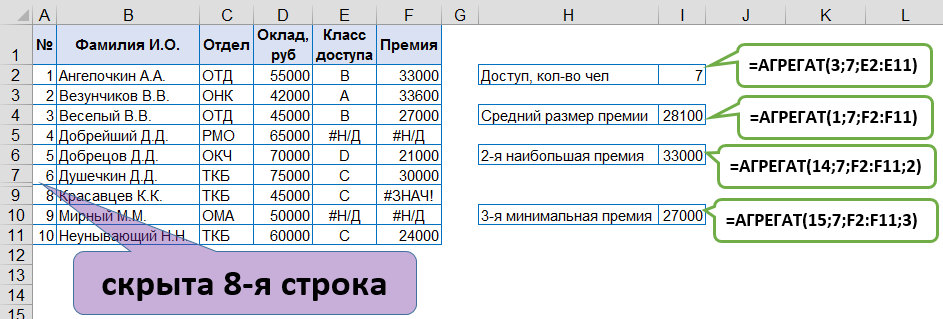
С помощью Проверки данных [Data Validation] можно организовать ввод данных путем выбора из предлагаемого списка, значения которого зависят от другого списка. Причем, используя функцию СМЕЩ [OFFSET] можно создать вариант, когда добавленные исходные значения будут отображаться в списках для выбора нужных значений. Если значения списка зависят от выбранного значения из другого списка, то можно создать связанный (зависимый) список нужных значений. Это позволит в значительной степени избежать не корректных комбинаций вводимых значений.
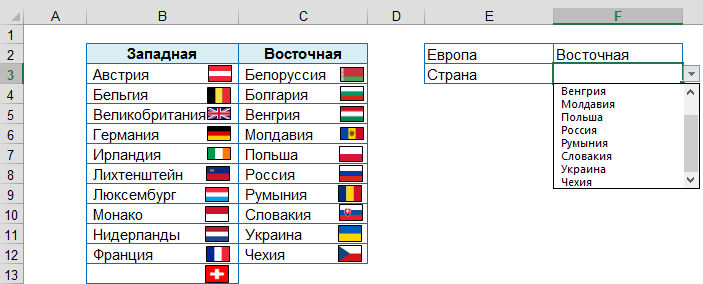
Например, в поле Европа происходит выбор одного из двух значений: Западная или Восточная, после этого в поле Страна предлагается список с соответствующими значениями.
Последовательность создания:
 Выделить ячейку F2, где будет выбираться Европа.
Выделить ячейку F2, где будет выбираться Европа.
На вкладке Данные [Data], в группе Работа с данными [Data Tools], выбрать Проверка данных [Data Validation] и на вкладке Параметры [Option], задать Условие проверки [Validation criteria] – Список [List], в качестве источника выделить ячейки B2 и C2

- Ячейкам значений стран (данные в столбцах B и C) необходимо присвоить имена – Западная и Восточная, с возможностью автоматического определения диапазона ячеек по мере изменения количества значений в соответствующих столбцах:
На вкладке Формулы [Formulas] выбрать Диспетчер имен [Name Manager] или нажать клавиши Ctrl+F3.
Создать имена с использованием функции СМЕЩ:
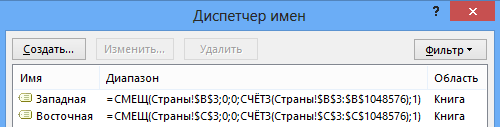
- Выделить ячейку F3, где будет выбираться Страна.
На вкладке Данные [Data], в группе Работа с данными [Data Tools], выбрать Проверка данных [Data Validation] и на вкладке Параметры [Option], задать Условие проверки [Validation criteria] – Список [List], в качестве источника ввести формулу:
=ЕСЛИ($F$2=»Западная»;Западная;Восточная)
[=IF ($F$2=»Западная»;Западная;Восточная)], где F2 – ячейка, которая содержит значение, выбираемого из первого списка.
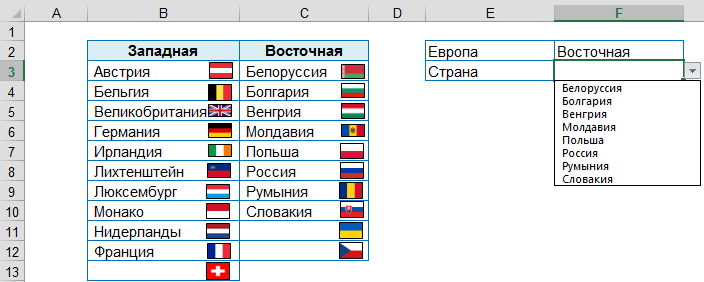
При добавлении новых данных, они будут сразу показаны в выпадающем списке:
Примечание: подразумевается, что элементы списка вводятся последовательно, т.е. элемент списка не содержит пустые ячейки.