Определение количества уникальных значений в диапазоне
| Категория: Приемы и советы, Формулы и функции | Опубликовано 05-04-2017
8
Для определение количества уникальных значений возможно по следующему сценарию: удалить дубликаты в копии диапазона, а затем воспользоваться функцией для подсчета количества значений с помощью функции СЧЁТЗ [COUNTA]. Однако, если исходные данные постоянно изменяются, то подобный сценарий придется повторять снова и снова.
И один из вариантов — это использовать формулы.
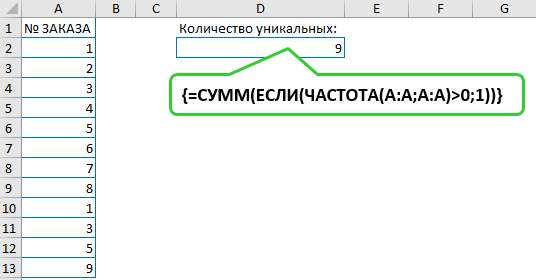
Среди стандартных функций, подобная не встречается. Но можно с использованием формулы массива создать такой алгоритм. По сути, нужно найти есть ли повторение данного элемента и, если есть, то суммировать.
Массив_интервалов — массив или ссылка на множество интервалов, в которые группируются значения аргумента «массив_данных».
{=СУММ(ЕСЛИ(ЧАСТОТА(A:A;A:A)>0;1))} или {=SUM(IF(FREQUENCY(A:A;A:A)>0;1))}
Подсчет количества уникальных числовых значений в диапазоне A:A без учета пустых ячеек и текстовых значений: