Функция АГРЕГАТ [AGGREGATE]
| Категория: Без рубрики, Приемы и советы, Формулы и функции | Опубликовано 30-09-2015
18
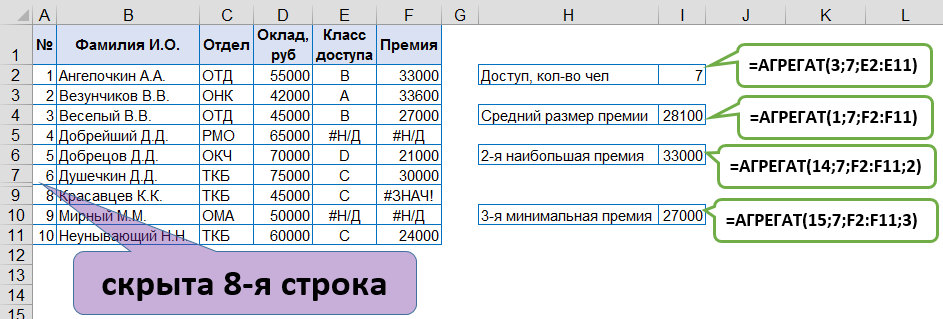
Исходные данные не всегда выглядят идеальными. В результате вычислений могут возникать различные типы ошибок, которые не всегда есть возможность заменить на какой-то альтернативный вариант решения. Плюс часто бывают ситуации, когда расчет надо вести только по отображенным (видимым) ячейкам. Всё это существенно усложняет процесс вычисления.
Функция АГРЕГАТ [AGGREGATE] стала доступна впервые в Excel 2010 версии. Можно считать ее расширенным вариантом множества статистических функций, которые определяют среднее, максимальное, минимальное и т.п. значения, т.к. она позволяет делать вычисления, игнорируя не только значения ошибок (эту проблему можно легко решить с использованием функции ЕСЛИОШИБКА [IFERROR] и формулы массива), но и скрытые ячейки.
Синтаксис функции:
АГРЕГАТ(Номер_функции;Параметры;Массив;[k])
[AGGREGATE(function_num;options;array;[k])]
- Номер_функции [function_num] изменяется от 1 до 19:
1 — СРЗНАЧ [AVERAGE]
2 — СЧЁТ [COUNT]
3 — СЧЁТЗ [COUNTA]
4 — МАКС [MAX]
5 — МИН [MIN]
6 — ПРОИЗВЕД [PRODUCT]
7 — СТАНДОТКЛОН.В [STDEV.S]
8 — СТАНДОТКЛОН.Г [STDEV.P]
9 — СУММ [SUM]
10 — ДИСП.В [VAR.S]
11 — ДИСП.Г [VAR.P]
12 — МЕДИАНА [MEDIAN]
13 — МОДА.ОДН [MODE.SNGL]
14 — НАИБОЛЬШИЙ [LARGE]
15 — НАИМЕНЬШИЙ [SMALL]
16 — ПРОЦЕНТИЛЬ.ВКЛ [PERCENTILE.INC]
17 — КВАРТИЛЬ.ВКЛ [QUARTILE.INC]
18 — ПРОЦЕНТИЛЬ.ИСКЛ [PERCENTILE.EXC]
19 — КВАРТИЛЬ.ИСКЛ [QUARTILE.EXC] - Параметры [options] — способ обработки ошибок и скрытых ячеек, изменяется от 0 до 7:
0 (по умолчанию) — Пропускать вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
1 — Пропускать скрытые строки и вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
2 — Пропускать значения ошибок, вложенные функций ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
3 — Пропускать скрытые строки, значения ошибок, вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
4 — Ничего не пропускать
5 — Пропускать скрытые строки
6 — Пропускать значений ошибок
7 — Пропускать скрытые строки и значения ошибок - Массив [array]- обрабатываемый диапазон данных
- [k] — позиция в массиве для функций: наибольшее, наименьшее, процентиль, квадратиль