Все уже привыкли, что в Excel присутствует автозавершение формул — это удобно, а к хорошему быстро привыкаешь. Достаточно ввести первые символы — программа предложит список функций, начинающиеся с этих символов.
Если в один прекрасный момент вы заметили, что автозавершение формул пропало, то стоит изменить настройку:
Открыть Файл [File], выбрать Параметры [Options], затем Формулы [Formulas], установить флажок Автозавершение формул [Formula AutoComplete]
Автор: Ольга Кулешова | Категория: Диграммы, Приемы и советы | Опубликовано 25-06-2017
4
Порой для анализа и лучшего понимания данных, стоит построить не только линии графика, но и показать зоны диапазонов с низкими, средними или высокими процентными диапазонами.
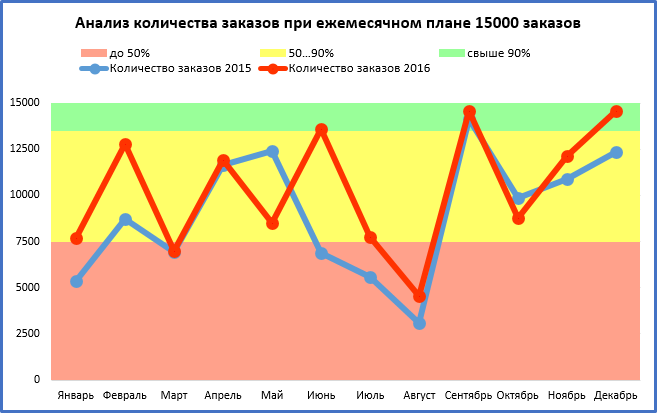
Пусть ежемесячный план составляет 15000 заказов. И рассмотрим три зоны процентовки:
— низкая до 50% (красная заливка на диаграмме);
— средняя от 50% до 90% (желтая заливка на диаграмме);
— высокая свыше 90% (зеленая заливка на диаграмме).
Подготовим таблицу исходных данных:
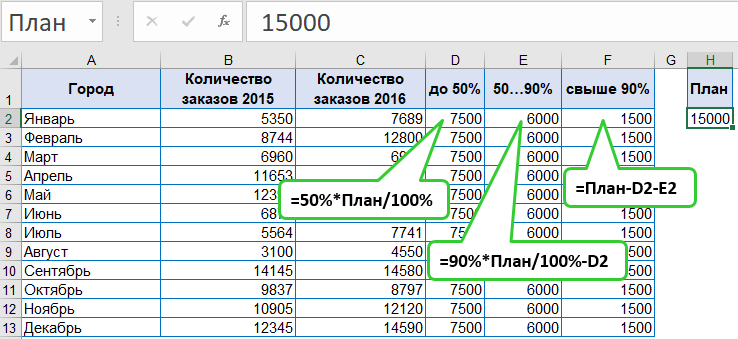
Для наглядности ячейке H2 со значением плана 15000 присвоено имя План. Но можно использовать в формуле и абсолютную ссылку $H$2.
По данным всей таблицы строим комбинированную диаграмму:
— график с маркерами для рядов с количеством заказов;
— гистограмма с маркерами для рядов с порогами %.
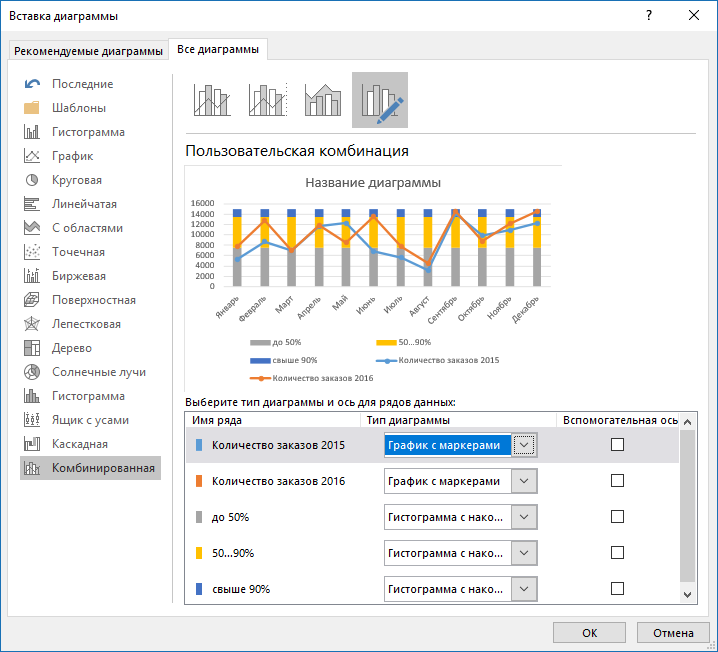
Остается навести немного красоты:
— задать боковой зазор 0% для гистограммы с накоплением (можно щелкнуть дважды по любому ряду и настроить в окне Формат ряда данных);
— изменить форматирование гистограмм в соответствии с принятыми обозначениями: красный, желтый и зеленый цвет заливки.
ГОТОВО!
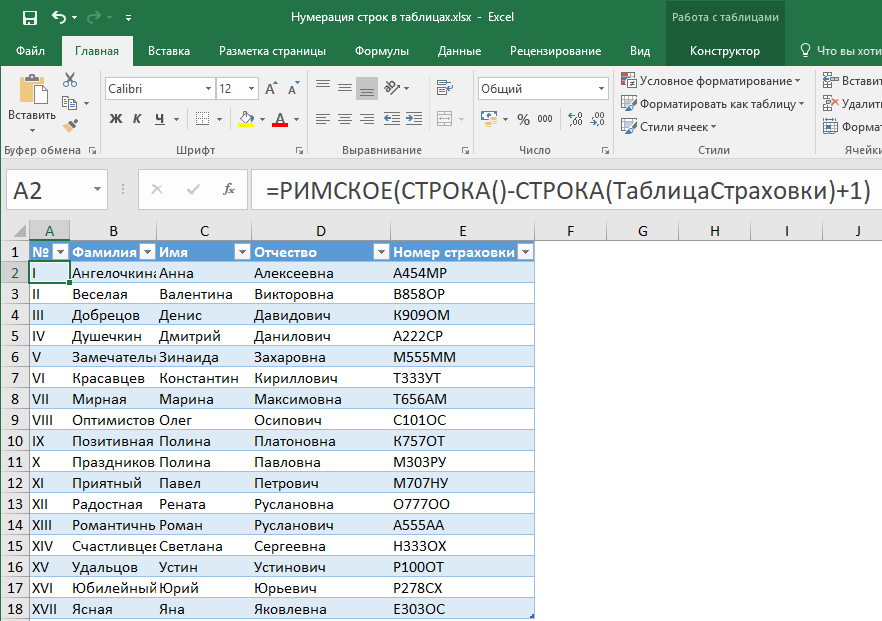
Рано или поздно возникает необходимость иметь в таблице автоматическую нумерацию записей (строк). В Word эта проблема решается просто — путем добавления нумерации любого вида: римскими или арабскими цифрами. В Excel нет таких возможностей. Однако использование структурированных таблиц и функции СТРОКА [ROW] из категории «Ссылки и массивы», позволяет легко решить эту задачу.
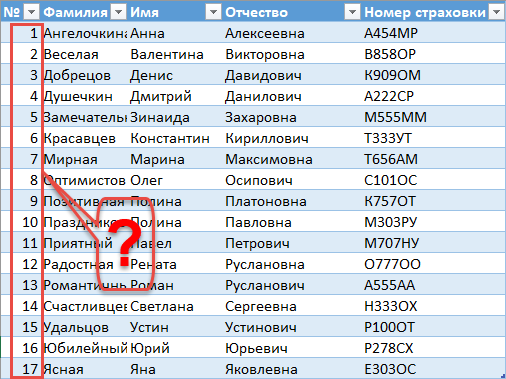
1). Обычный диапазон ячеек должен быть преобразован в табличный вид, например, используя комбинацию клавиш Ctrl+T.
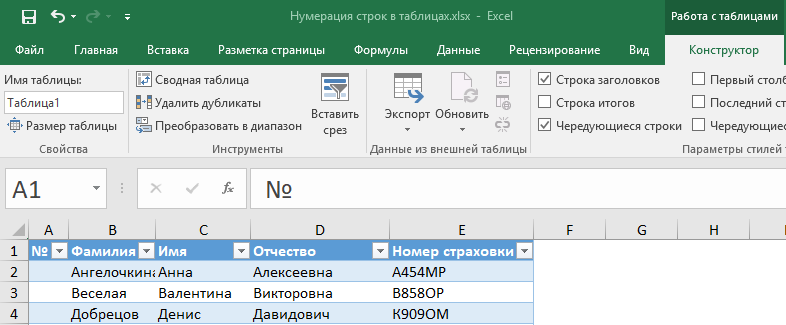
2) Для удобства работы таблицу можно переименовать — для этого на вкладке Конструктор [Design] в группе Свойства [Properties] в поле Имя таблицы [Table Name] ввести имя (без пробела) и нажать Enter. Например, ТаблицаСтраховки.
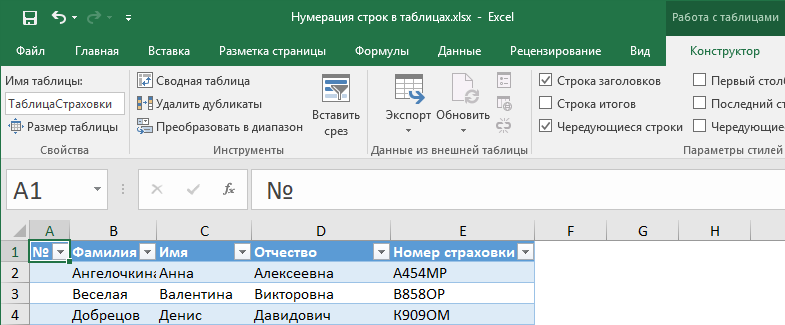
3) В 1-ю ячейку поля № ввести формулу:
=СТРОКА()-СТРОКА(ТаблицаСтраховки)+1 или
=ROW()-ROW(ТаблицаСтраховки)+1 для англоязычной версии.
Формула автоматически будет скопирована по всему полю.
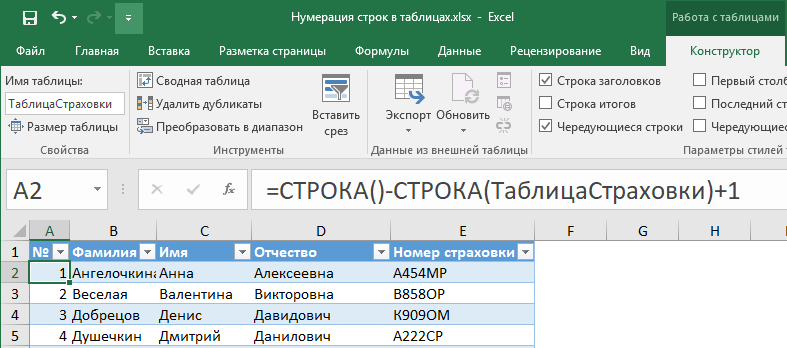
Нумерация готова!
Если необходимо нумерацию сделать римскими цифрами, то следует в начало формулы добавить функцию РИМСКОЕ [ROMAN]:
=РИМСКОЕ(СТРОКА()-СТРОКА(ТаблицаСтраховки)+1) или
=ROMAN(ROW()-ROW(ТаблицаСтраховки)+1) для англоязычной версии.