С помощью Проверки данных [Data Validation] можно организовать ввод данных путем выбора из предлагаемого списка, значения которого зависят от другого списка. Причем, используя функцию СМЕЩ [OFFSET] можно создать вариант, когда добавленные исходные значения будут отображаться в списках для выбора нужных значений. Если значения списка зависят от выбранного значения из другого списка, то можно создать связанный (зависимый) список нужных значений. Это позволит в значительной степени избежать не корректных комбинаций вводимых значений.
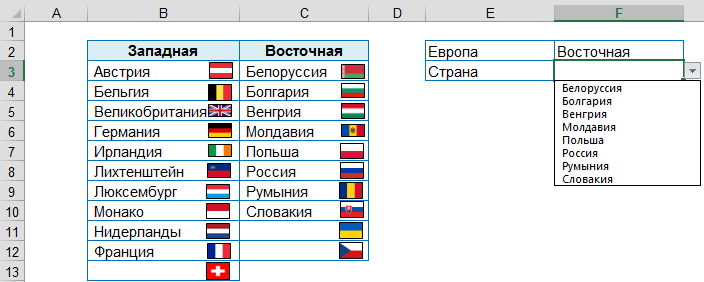
Например, в поле Европа происходит выбор одного из двух значений: Западная или Восточная, после этого в поле Страна предлагается список с соответствующими значениями.
Последовательность создания:
 Выделить ячейку F2, где будет выбираться Европа.
Выделить ячейку F2, где будет выбираться Европа.
На вкладке Данные [Data], в группе Работа с данными [Data Tools], выбрать Проверка данных [Data Validation] и на вкладке Параметры [Option], задать Условие проверки [Validation criteria] – Список [List], в качестве источника выделить ячейки B2 и C2

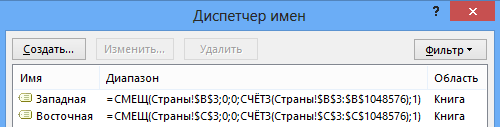
- Ячейкам значений стран (данные в столбцах B и C) необходимо присвоить имена – Западная и Восточная, с возможностью автоматического определения диапазона ячеек по мере изменения количества значений в соответствующих столбцах:
На вкладке Формулы [Formulas] выбрать Диспетчер имен [Name Manager] или нажать клавиши Ctrl+F3.
Создать имена с использованием функции СМЕЩ:
- Выделить ячейку F3, где будет выбираться Страна.
На вкладке Данные [Data], в группе Работа с данными [Data Tools], выбрать Проверка данных [Data Validation] и на вкладке Параметры [Option], задать Условие проверки [Validation criteria] – Список [List], в качестве источника ввести формулу:
=ЕСЛИ($F$2=»Западная»;Западная;Восточная)
[=IF ($F$2=»Западная»;Западная;Восточная)], где F2 – ячейка, которая содержит значение, выбираемого из первого списка.
При добавлении новых данных, они будут сразу показаны в выпадающем списке:
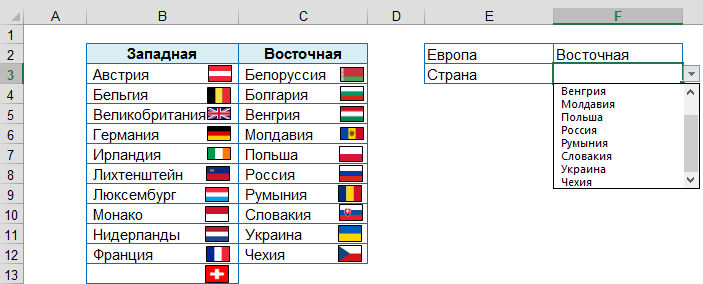
Примечание: подразумевается, что элементы списка вводятся последовательно, т.е. элемент списка не содержит пустые ячейки.
Ситуация довольна простая. По источнику данных происходит построение отчета сводной таблицы. Затем в источнике происходит изменение данных, но при обновлении отчета в фильтрах видны как прежние, так и новые значения. Как избавиться от «старых» (прежних) данных?
Например, строим отчет по источнику, в котором есть данные 4-х городов:
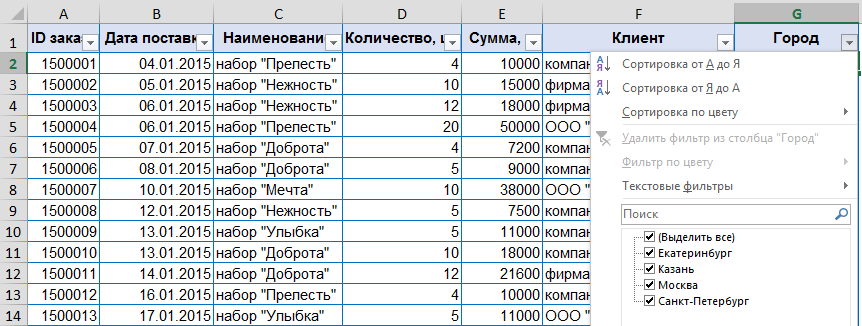
и получаем:
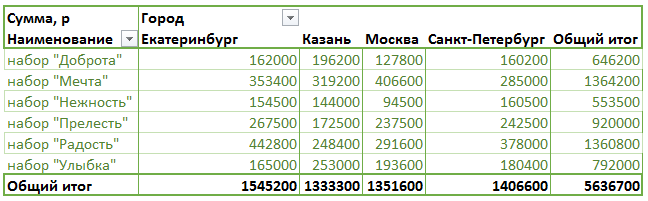
Теперь произведем замену в исходных данных, например, город Казань заменим на Ульяновск:
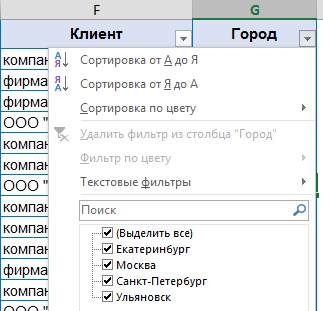
Однако, выполнив команду Обновить [Refresh] в сводной таблице (клавиши Alt+F5), данные отображаются в ячейках корректно в соответствии с данными источника:
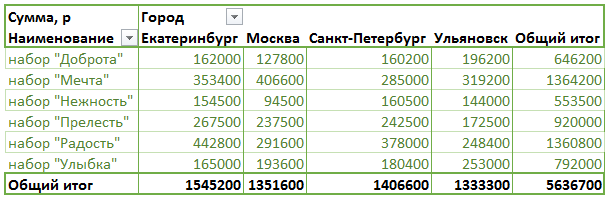
но в фильтрах осталось и прежнее значение — Казань:
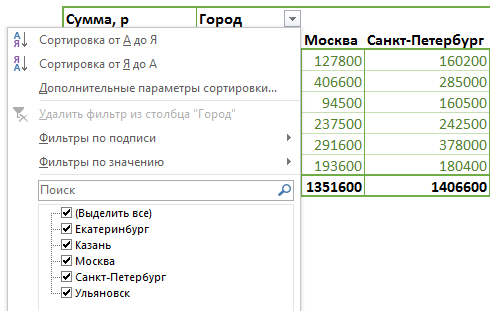
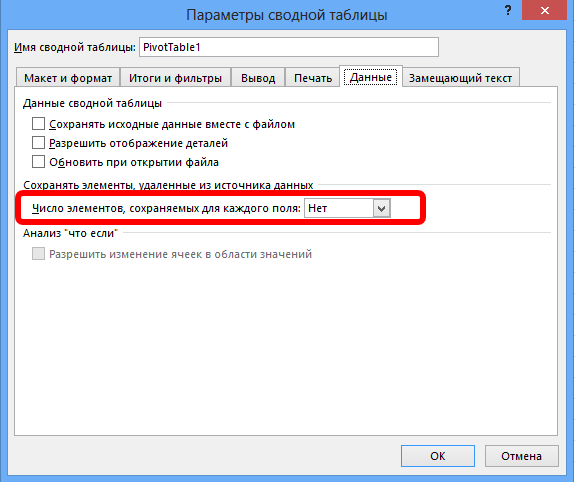
Чтобы убрать из фильтра уже не существующие данные, следуют в контекстном меню отчета выбрать команду Параметры сводной таблицы [PivotTable Options] и на вкладке Данные [Data] в списке Число элементов, сохраняемых для каждого поля [Number of items to retain per field] выбрать Нет [None].
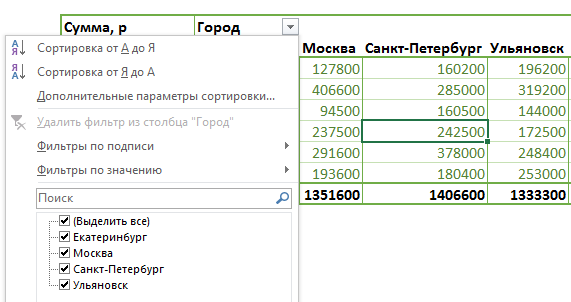
выполнить обновление (Alt+F5), после чего элементы в фильтре содержатся актуальные:
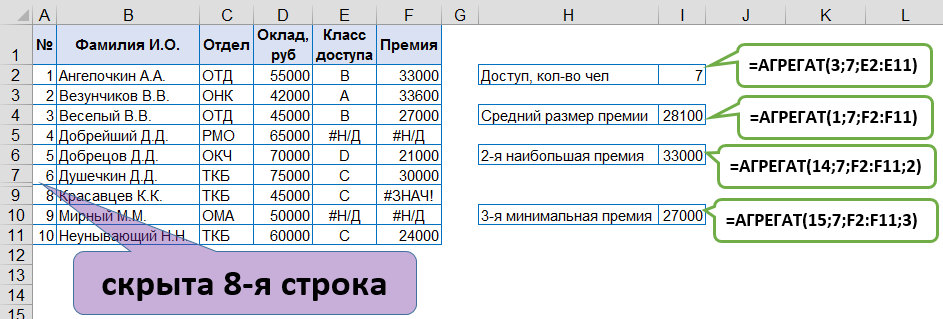
Исходные данные не всегда выглядят идеальными. В результате вычислений могут возникать различные типы ошибок, которые не всегда есть возможность заменить на какой-то альтернативный вариант решения. Плюс часто бывают ситуации, когда расчет надо вести только по отображенным (видимым) ячейкам. Всё это существенно усложняет процесс вычисления.
Функция АГРЕГАТ [AGGREGATE] стала доступна впервые в Excel 2010 версии. Можно считать ее расширенным вариантом множества статистических функций, которые определяют среднее, максимальное, минимальное и т.п. значения, т.к. она позволяет делать вычисления, игнорируя не только значения ошибок (эту проблему можно легко решить с использованием функции ЕСЛИОШИБКА [IFERROR] и формулы массива), но и скрытые ячейки.
Синтаксис функции:
АГРЕГАТ(Номер_функции;Параметры;Массив;[k])
[AGGREGATE(function_num;options;array;[k])]
- Номер_функции [function_num] изменяется от 1 до 19:
1 — СРЗНАЧ [AVERAGE]
2 — СЧЁТ [COUNT]
3 — СЧЁТЗ [COUNTA]
4 — МАКС [MAX]
5 — МИН [MIN]
6 — ПРОИЗВЕД [PRODUCT]
7 — СТАНДОТКЛОН.В [STDEV.S]
8 — СТАНДОТКЛОН.Г [STDEV.P]
9 — СУММ [SUM]
10 — ДИСП.В [VAR.S]
11 — ДИСП.Г [VAR.P]
12 — МЕДИАНА [MEDIAN]
13 — МОДА.ОДН [MODE.SNGL]
14 — НАИБОЛЬШИЙ [LARGE]
15 — НАИМЕНЬШИЙ [SMALL]
16 — ПРОЦЕНТИЛЬ.ВКЛ [PERCENTILE.INC]
17 — КВАРТИЛЬ.ВКЛ [QUARTILE.INC]
18 — ПРОЦЕНТИЛЬ.ИСКЛ [PERCENTILE.EXC]
19 — КВАРТИЛЬ.ИСКЛ [QUARTILE.EXC]
- Параметры [options] — способ обработки ошибок и скрытых ячеек, изменяется от 0 до 7:
0 (по умолчанию) — Пропускать вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
1 — Пропускать скрытые строки и вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
2 — Пропускать значения ошибок, вложенные функций ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
3 — Пропускать скрытые строки, значения ошибок, вложенные функции ПРОМЕЖУТОЧНЫЕ.ИТОГИ и АГРЕГАТ
4 — Ничего не пропускать
5 — Пропускать скрытые строки
6 — Пропускать значений ошибок
7 — Пропускать скрытые строки и значения ошибок
- Массив [array]- обрабатываемый диапазон данных
- [k] — позиция в массиве для функций: наибольшее, наименьшее, процентиль, квадратиль